存储模型 --- Bitcask
存储模型 --- Bitcask
简介
在面向磁盘的Key/value数据库设计中,常见存储模型的有B+Tree,LSM,前者读性能优秀,后者写性能优秀,它们两个已经有了非常多的实践案例,比如基于B+Tree的BoltDB,基于LSM的LevelDB。不过今天的主角讲的并不是它们两个,而是另一个存储模型Bitcask,它最早是由一个日本分布式存储公司Riak提出的理论,与LSM类似,它也是日志结构,不过实现起来要比LSM简单的多。
Bitcask文档:riak-bitcask
Riak公司最初希望寻找一个满足以下条件的存储引擎
- 读写低延迟
- 高吞吐量随机写入
- 在高负载情况下,行为可以预测
- 具有处理比内存更大空间数据的能力
- 崩溃友好,可以快速恢复而不丢失数据
- 易于备份和恢复
- 简单易懂的数据格式,且易于实现
- 简单的使用协议
找到满足上面部分条件的很容易,但是满足全部条件的几乎没有,于是这促使他们开始自己去研究一种日志化结构的KV存储引擎,受到LSM的启发,而后便设计了Bitcask这一个可以满足上述所有要求的存储模型,所以Bitcask实际上也是一种类LSM的结构。
设计
在了解完Bitcask的历史后,下面来说说它究竟是如何设计的。
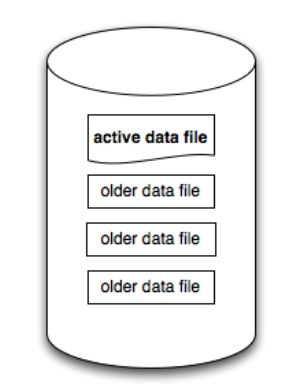
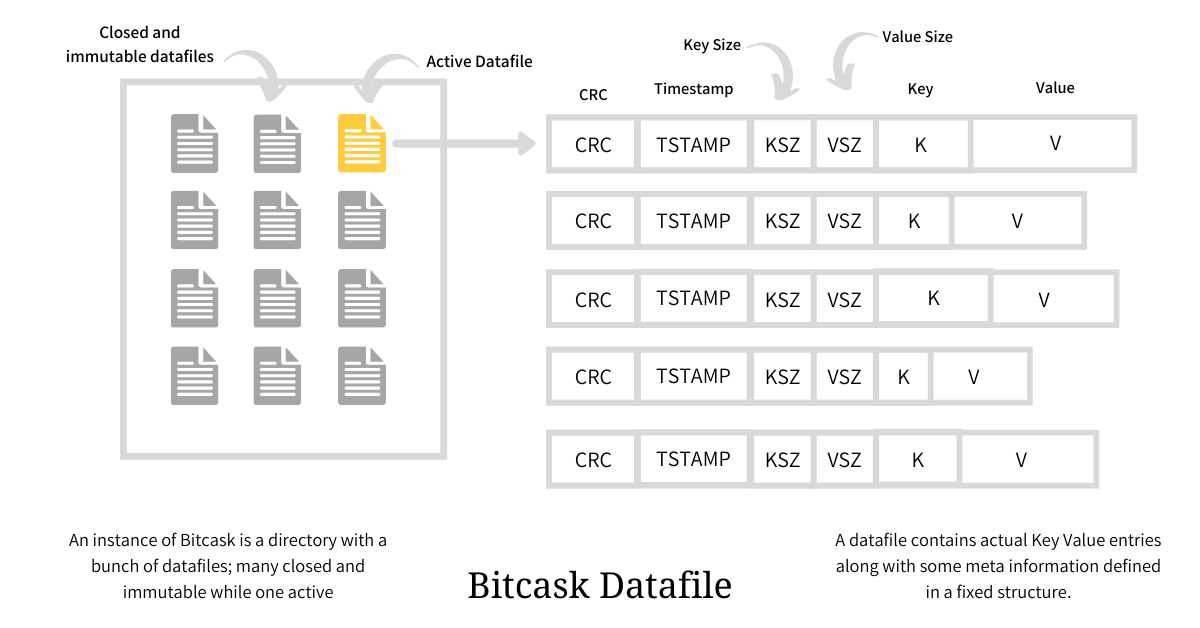
一个Bitcask实例就是一个文件夹,文件夹存放着若干个数据文件,这些文件分为Active Data File和Older Data File。在某一时刻,数据会被写入到Active Data File也就是活跃文件,当文件存放的数据达到阈值后,当前活跃文件将被关闭并成为旧数据文件,旧数据文件一旦被关闭过后,日后永远都不会再对其写入数据。然后会创建一个新的活跃数据文件用于写入新数据,同一时刻只能有一个进程对活跃数据文件写入数据。文件的写入操作是通过追加(append only)的方式进行,由于是顺序IO所以不需要多余的磁盘寻址操作。
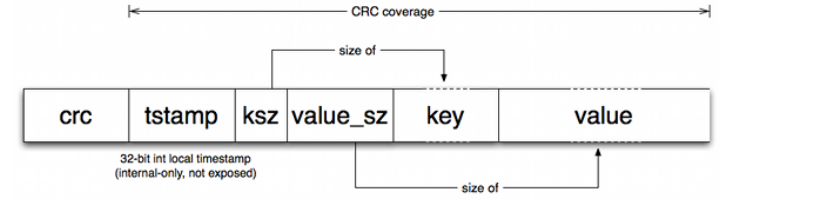
Bitcask的数据格式同样很简单,如图所示,由以下几个部分组成
- crc,循环冗余校验码
- tstamp,时间戳
- ksz,键的所占用的空间大小
- value_sz,值所占用的空间大小
- key,存放键
- value,存放值
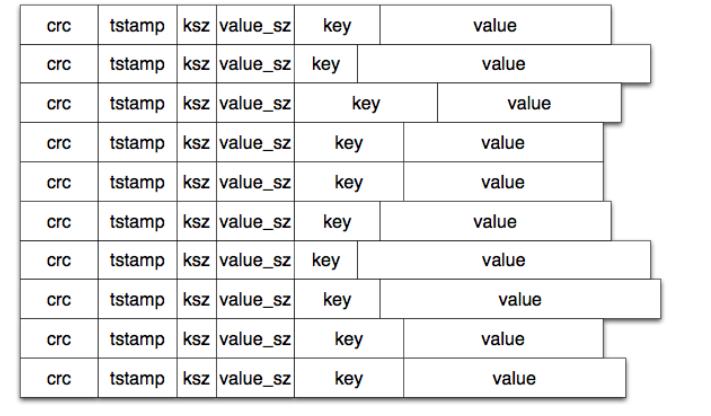
每一次对活跃数据文件写入数据,就会添加一条新的数据条目,对于删除操作而言,并不会真的去删除文件里面的数据,而且将其作为一个特殊的数据条目写入文件中来标记该数据被删除,待到下次文件合并时,数据才会被真正的删除。Bitcask数据文件只不过是这些数据条目的线性序列,如下图所示。
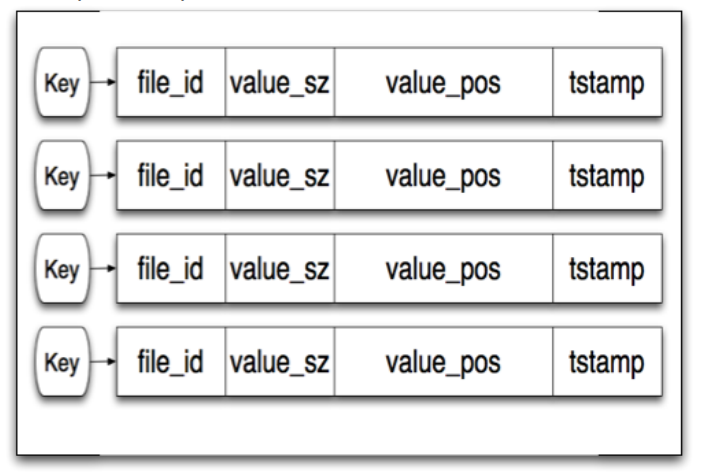
在向磁盘写完数据以后,就会去更新keydir"。"keydir"并不是一个真的文件夹,它是一个维护在内存中的索引结构,负责映射每一个key的元信息。这些元信息包括
- file_id,标识数据存放在哪一个文件
- value_sz,数据所占用的空间大小
- value_pos,数据在文件中的位置
- tstamp,时间戳
如下图所示
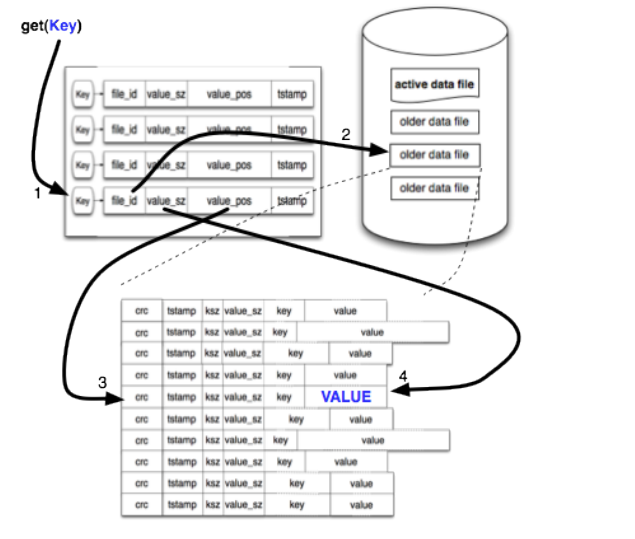
当更新数据时,并不会去更新旧数据文件中的指定数据条目,而是向当前的活跃数据文件添加新的数据条目,然后keydir会原子的更新最新数据的位置,旧数据依旧保存在磁盘中,往后的数据读取操作会使用keydir中的最新位置来进行访问,至于旧数据条目会在后续的合并过程中被删除。
对于读数据而言,只需要进行一次磁盘寻道。首先会从内存中维护的keydir找到与之匹配的数据元信息,得知数据存放在哪一个文件,以及文件中的位置信息,然后再去对应的数据文件中读取响应的数据条目信息,凭借着操作系统的预读文件缓存,这一过程可能会比预期的还要更快。
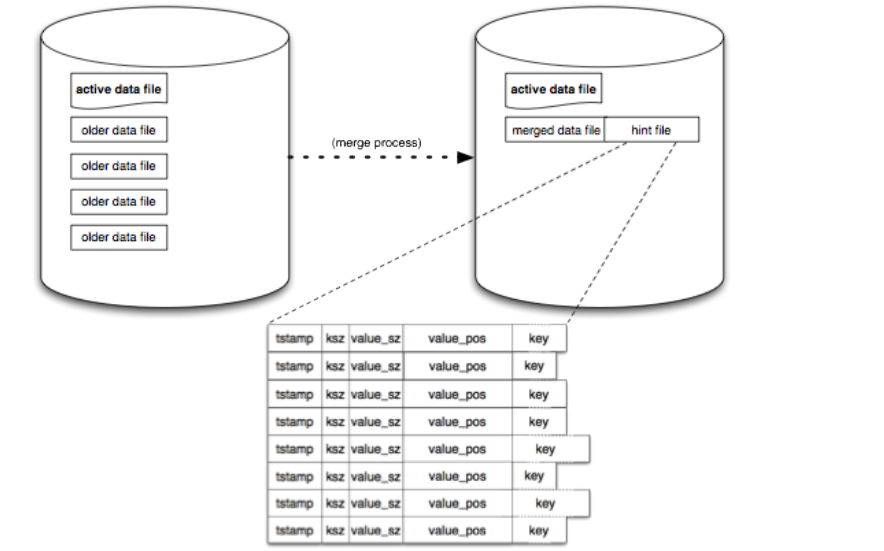
在上面的删除和更新操作中,都会产生额外的新数据条目,对于旧数据条目则不会再使用,随着时间的推移,这种冗余的数据条目会越来越多,就会占用相当大一部分的空间,为此需要就需要去清理这些旧的数据文件,这个过程就称之为合并。在合并过程中,会遍历所有的旧数据文件,然后输出一系列只包含最新数据的文件,在合并的同时,还会创建Hint File,也就是索引文件,每一个合并过后的Merged Data File都有一个对应的Hint File,Hint File中的数据条目与内存中的keydir相对应,前者是后者的持久化体现。Hint File只存储数据元信息,并不存储实际的数据,它的作用是为了在Bitacask实例启动时,更快速的构建内存索引。
这些就是Bitcask所有的设计内容,可以看得出确实比较简单和容易理解。官方还做了以下几点的说明
- Bitcask读性能依赖于操作系统的文件系统缓存,他们曾经讨论设计过关于Bitcask的内部缓存,这可能会使Bitcask变得更复杂,且不清楚这样做的带来的性能收益是否可以抵过随之而来的复杂性,毕竟设计的初衷就是要足够简单。
- Bitcask不会对数据进行任何的压缩,因为这种行为的收益与损耗依赖具体的应用。
- 在早期的测试中,一台低配的笔记本电脑上,Bitcask每秒可以执行5000-6000次左右的写入操作。
- 在早期的测试中,Bitcask可以存储10倍于内存的数据而不会出现性能下降的情况。
- 在早期的测试中,即便有数百万个key,keydir所占用的内存也不到GB。
总结
Bitacask在设计之初就不是追求最快的速度,作者觉得快到足够使用即可,它使用内存来做索引,用磁盘来存储数据,具有实现简单,可读性强,性能优秀等众多优点。由于它只有一个写入点,且只能是串行写入,所以尤其适合存储大量只需一次IO就能写入的小块数据,对于大块数据而言,会使得吞吐量非常低。
鉴于其简单的设计,非常适合初学者学习和入门,社区里面也有很多开源实现,比如nutsDB,roseDB,两者都是嵌入式KV数据库,均为go语言实现。动手自己实现一个基于Bitacask的数据库,可以加深理解。
API
Riak官方在文档中描述了Bitcask参考的API,仅仅只有几个接口,下面以go语言的伪代码展示。
type BitCask interface {
// 创建一个新的bitcask实例
Open(dir) (db, error)
// 获取指定的键值
Get(key) (value, error)
// 新建或插入键值
Put(key, value) (value, error)
// 删除指定的键值
Delete(key) (value, error)
// 列出所有可用的键
List() ([]key, error)
// 迭代键值
Fold(fn) error
// 合并
Merge(dir) error
// 同步磁盘
Sync() error
// 关闭实例
Close() error
}