RiverDB
RiverDB

开头
大概在11月份,我写了两篇文章,一篇讲的是Bitcask,另一个讲的是Write Ahead Log,这两个东西跟数据库都有着莫大的关系。写完以后,我便萌生了一个想法,能不能自己动手写一个数据库,因为在此前数据库对我来说都只是使用而已,写一个数据库似乎有点遥不可及,并且从来没有接触过这些。想到就做,于是我花了点时间去参考了Github上比较知名的开源数据库包括:Badger,LevelDB,godis,RoseDB,NutsDB等
主流数据库的存储模型有B+Tree和LSM,最终选择了使用Bitcask存储模型来作为我的入门选择,它就像是简化版的LSM,因为它足够简单,不至于太难一上来直接劝退,也是我选择它的一大原因,准备妥当后,便开始着手朝着这个未知的领域窥探一番。
正所谓万事开头难,第一个问题就是数据库叫什么名字,虽然写出来可能没人用,但好歹要有一个名字。在思索一番过后,决定取名为river,这个名字来自初中时候玩的一款游戏《去月球》,里面的女主就叫river。在建完github仓库后,便开始思考一个数据库要有什么,首先可以确定的是这是一个KV数据库,最基本的增删改查肯定是要保证的,然后就是TTL可以整一个,给键值上一个过期时间,既然有了TTL,肯定要能单独查询和修改TTL的功能,还有一个最最重要的就是事务支持,以及批量写入数据和批量删除数据,梳理一下就是
- 基本的增删改查
- TTL过期时间支持
- 事务支持
- 批量处理数据
- 范围扫描和匹配
对了还有一个忘了就是数据库的备份和还原,这个也蛮重要的,在梳理好了这些大体的功能以后就可以开始着手去设计一些细节了。
存储
首先就是如何在磁盘上存放数据,既然采用了Bitcask作为存储模型,那么最简单直接的方法就是一条一条record存,一条一条record读,这样做最简单,也最容易实现。但是!非常重要的一点就是,前面已经提到过Bitcask不适合存大块数据,在几MB以上数据就可以被称为大块数据了,Bitcask原有的Record是由几个部分组成
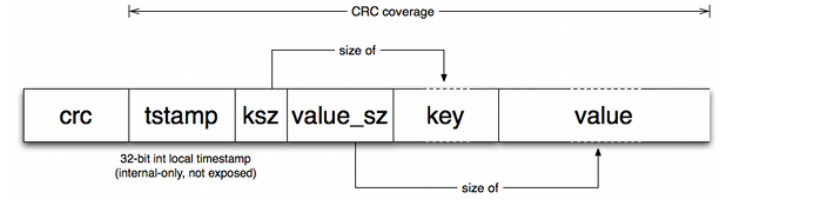
header部分主要是record的元数据,包括crc,时间戳,key的长度,value的长度,读取一条record,需要两次IO,第一次读header,确认数据的长度,第二次确认数据长度过后才能去读取数据。实际上存放的数据都不是特别大,平均可能只有KB级别,甚至不到KB,对于这样小的数据,读取一条record还要进行两次IO,十分的浪费性能。
那么可以这样考虑,一次读取固定大小的文件内容到内存中,称之为Block,然后在内存中从Block读取数据,如果数据的足够小,刚好能在Block中,那么查询就只需要一次IO,后续虽然也是要先读数据长度再读实际数据,但由于是在内存中读取,要比磁盘读取快得多,这种能被Block容纳的数据称之为Chunk。而这个规则也就是应用在LevelDB的Wal文件中,而LevelDB默认的BlockSize就是32KB,每一次IO固定读32KB,这个值太大了会耗费内存,太小了会频繁IO。

一个chunk由header和data组成,header最大为7个字节,所以data数据长度范围在[0, 32KB-7B],这里将crc校验从record抽离出来,放到了chunk中,这样在读写数据的时候就不需要再去做额外的校验。所以数据库实际操作的record是存放在data这部分中,对于一条记录而言,它的头部由以下几个部分组成
- type,标识操作类型,更新还是删除
- ttl,过期时间,存放的是毫秒,10个字节是64位整数占用的最大字节数
- txn_id,事务ID
- key_sz,key的长度,5个字节是32位整数所需要的最大字节数
- val_sz,数据的长度
数据的组织格式大体上就设计完毕了,数据在文件中的分布大概可能是下图的样子

除此之外,我还在内存中做了一个缓存,由于每次读取的都是一个32KB的Block,那么可以将频繁使用的Block缓存起来从而减少了IO次数。思考这么一种情况,如果一个Block中的所有Chunk都远小于Block,那么只有读第一个Chunk的时候,会进行文件IO,在第一个chunk读取完毕后,会将这个Block缓存起来,这样一来,后续的Chunk就不再需要从文件中读取,直接从内存里面读取即可,这样就大大提高读取的速度。但一直缓存也不是办法,内存也是有限的,也还要做索引,所以需要定期进行淘汰,这里可以用LRU缓存来实现。
使用了上述的数据组织形式,可以一定程度上优化读的性能,不过写性能也不能忽略。Bitcask本身采用的是append-only的写入方式,顺序写的性能自然是要比随机写要好很多的,不过问题在于这样会包含很多冗余的数据。写性能的瓶颈在与Fsync的时机,如果每一次写入都sync,数据的持久性可以得到很好的保证,但性能会很低,如果不sync,性能肯定是比前者要高很多的,但持久性难以得到保证,正所谓鱼和熊掌不可得兼,还得是在两者之间找一个平衡点。
索引
对于索引的选择,比较主流的选择有BTree,SkipList,B+Tree,RedBlackTree,这几个都有一个共同点就是它们都是有序的,当然还有一个无序的数据结构哈希表,这个直接排除了,使用哈希表做索引没法做范围扫描。Redis和LevelDB首选的是SkipList,基于有序链表的SkipList的写性能会优秀一些,查询性能相对较弱,而树这一类的数据结构查询性能优秀,写入性能相对而言弱一些。
考虑到Bitcask存储模型并不适合存储大量数据,也不适合存储大块数据,在综合考虑下,选择了各方面比较平衡的BTree作为首选的内存索引,BTree又叫做多路平衡查找树,不选SkipList是因为没有找到很好的开源实现,B+Tree更适合做磁盘索引,而Btree有谷歌开源的库,并且另一大优点就是这个库很多人使用且支持泛型。不过其实索引并不只限于BTree,索引这一层做了一层抽象,后续也可以用其它数据结构实现。
是否要自己手写?说实话这个数据库我还是想用一用的,BTree,B+Tree都是非常复杂的数据结构,自己写是能写但不一定能保证能用,有了稳定成熟的开源实现可以使用是最好的。我自己也有写另一个数据结构的库,并且全都支持泛型,
开源仓库:246859/containers: base data structure and algorithm implemention in go genericity (github.com)
不过还在逐步完善,等以后稳定了说不定可以使用。
那么,内存索引存什么东西呢?这个问题还是比较好回答的,考虑到存储中采用的是Wal的组织形式,索引中存储的信息应该有
- 哪个文件
- 哪个block
- chunk相对于block的offses
用go语言描述的话就是一个结构体
type ChunkPos struct {
// file id
Fid uint32
// chunk in which block
Block uint32
// chunk offset in block
Offset int64
}
每一个block固定为32KB,所以只需要知道Fid,BlockId,Offset这三个信息就可以定位一条数据。除此之外,还可以把数据的TTL信息也放到索引中存储,这样访问TTL就不需要文件IO了。
事务
如果要我说整个数据库哪一个部分最难,恐怕只有事务了,支持事务要满足四个特性,ACID,原子性(Atmoicty),一致性(Consistency),隔离性(Isolation),Durability(持久性)。其中最难实现的当属隔离性,隔离性又分为四个级别,读未提交,读提交,可重复读,串行化。
在写事务这块之前,参考了下面几个项目
RoseDB
它的v2版本对于事务的实现只有一个读写锁,保证了串行化事务。
NutsDB
跟上面的一样,也是用一个读写锁来实现串行化事务,可以并发读,但是不能并发写,并且写会阻塞读写事务。
Badger
badger与上面的两个项目不同(吐槽一下badger源代码可读性有点差),它是基于LSM而非Bitcask,并且提供了完整的MVCC事务支持,可以并发的进行读写事务,失败就会回滚。
前两个数据库不支持MVCC的理由非常简单,因为Bitcask本身就使用内存来做索引,如果实现MVCC事务的话,就需要在内存中存放许多版本的索引,但是内存空间不像磁盘,磁盘空间多用一点没什么,所以Bitcask的存储方式会产生冗余数据是可以容忍的,但内存空间是非常宝贵的,采用MVCC事务的话会导致有效索引的可用空间受到非常大的影响。
大致的思路如下,在开启一个事务时不需要持有锁,只有在提交和回滚的时候才需要。在一个事务中所有的修改加上事务ID后都将立即写入到数据文件中,但是不会更新到数据库索引中,而是去更新事务中的临时索引,每一个事务之间的临时索引是相互独立的,无法访问,所以事务中更新的数据对外部是不可见的。在提交时,首先检测是否发生了事务冲突,冲突检测思路如下。
遍历所有已提交的事务
检测其提交时间是否晚于本次事务的开始时间
如果是的话,再遍历该事务的写集合,如果与本次事务的读集合有交集,说明本次事务中读过的数据在事务执行过程中可能被修改了,于是判定为发生冲突。
提交成功的话就加入已提交事务列表中
将事务中的临时索引更新到数据库索引中,现在数据对外部可见了
插入一条特殊的记录,附带上当前事务的事务ID,表示此次事务已提交
如果失败回滚的话,也插入一条特殊的记录,表示此次事务已回滚
数据库在启动时,会按顺序遍历每一个数据文件中的每一条数据,每一个数据都携带对应的事务ID,首先会收集对应事务ID的事务序列,如果读到了对应事务ID的提交记录,就会将该事务的数据更新到内存索引中,如果读到了回滚的记录就会直接抛弃。如果一个事务序列,既没有提交也没有回滚,这种情况可能发生在突然崩溃的时候,对应这种数据则直接忽略。
这样一来,事务的ACID都可以满足了
- 原子性和一致性,只有提交成功的数据才会出现在索引中,回滚和崩溃的情况都会直接抛弃,所以只有成功和失败两种结果,即便出现突然断电崩溃,也不会出现第三种状态。
- 持久性:一旦事务提交成功,也就是标记事务提交的特殊记录写入到数据库中,那么这些数据在数据库中就永远生效了,不管后面突然断电还是崩溃,在数据库启动时这些事务数据一定会成功加载到索引中。
- 隔离性:事务与事务之间的修改是彼此都不可见的,只有提交后更新到索引中,所做的修改才能被其它事务看见。
在运送时,可以用最小堆来维护当前的活跃事务,在每一次提交后就会清理已提交事务列表,如果提交时间小于堆顶的事务开始时间,说明该事务不可能会与活跃的事务发生冲突,就可以将其从已提交事务列表中删除,避免该列表无限膨胀。
但是!凡是都要有个但是,上面这种方法的隔离级别只能够保证读提交,无法保证可重复读,如果读过的数据在事务执行过程中被修改了,就会发生冲突,这种情况要么回滚要么重试。当然,riverdb也提供了另一个隔离级别,串行化,就跟RoseDB和NutsDB一样,使用读写锁来保证事务之间按照顺序执行,这样做的好处就是几乎很难发生冲突,坏处某一时刻就是只有一个协程能写入数据。
高性能往往意味着的可靠性低,高可靠性也代表着性能会拖后腿,事务就是可靠性和性能之间的权衡,至于选择什么隔离级别,这个可以做成可配置化的,让使用者自己选择。
合并
在存储那一块提到了增量写导致的问题,由于不管是增删改,都会插入一条新的数据,随着时间的流逝冗余的数据越来越多,肯定需要去清理的,不然会占用大量的空间。对数据库中无用的数据进行清理,这一过程称为合并。在合并清理数据的时候,有几个问题需要思考
- 清理哪些数据
- 在什么时候清理
- 如何清理
清理哪些数据?梳理了一下应该有下面这些数据
- 过期的数据,已经过期的数据是没有必要再存在的
- 被覆盖的数据,有效的数据始终只有一条,被覆盖后没有存在的必要
- 被删除的数据,删除后也不需要了
- 回滚的事务数据
- 无效的事务数据,也就是写入数据,但是即没提交也没回滚
对于事务数据,成功提交后的事务数据在清理时可以将其事务ID清空,在数据库启动时读取数据时,读到合并后的数据可以直接更新到索引中,而不需要收集整个事务序列来判断是否提交成功。
在什么时候清理?肯定是不能直接在原数据文件上动手,否则的话会阻塞其它正在进行的读写操作,一个Bitcask实例本身就是一个文件夹,数据库本身就是一个Bitcask示例,为了不阻塞读写,可以在清理合并数据的再新建一个Bitcask实例,将清理后的数据写入到新的实例中,然后再将数据覆盖到数据库实例中,这样的好处就是只有在进行覆盖操作的时候才会阻塞读写操作,其它时候不影响。
如何清理?在清理开始之前可以让bitcask实例新建一个active-file,将当前文件归入immutable-file,这样一来,在清理过程中新的写入就会写入到新的active-file中,而清理操作则是针对旧的immutable-file,记录下旧的active-file的文件id,然后逐个遍历immutable-file,如果数据被删除了,索引中自然不会存在,数据是否过期需要在遍历时判断一下,另一个需要注意的一点是还要检查一下索引信息中的文件id是否大于记录的文件id,是的话说明是新的写入操作则忽略掉这个索引项。在遍历索引时,还可以做一件额外的事,那就是构建hint文件,将新的索引信息写入hint文件中,这样一来,在数据库启动期间构建索引时,对于清理后的这部分数据可以不用去遍历每一条数据,而且可以从hint文件中读取,对于未清理的数据仍然需要去遍历其真实数据,这样做可以加快内存的构建速度。对于hint文件,它就等于存放在磁盘中的索引,其中的每一条记录都只存放索引信息,不包含实际数据,它只用于构建索引,而不会用于数据查询,目的只是为了加快索引的构建速度。
当数据清理完毕后,根据先前记录的文件ID覆盖掉原先的immutable-files,然后在重新加载索引,这样一来合并过程就完成了。还剩下最后一个问题,合并操作该在什么时候进行?有两个方案,第一个是定时合并,另一个是触发点。定时合并就比较简单了,就只是定时操作。触发点则是让数据库在写入时记录数据条数,当现有的数据条数与索引中的条数达到一定比例时就会触发合并。触发点合并就需要考究了,如果数据库中的数据量本身就很小,比如只有100条,但这100条都是针对一个key的改写,那么比例就达到了100:1,可能会触发合并,但实际上根本就没有必要。那么该如何去判断是否达到了触发点呢,这个可以用事件监听来实现,监听数据库的写入行为,如果达到了阈值,就可以进行合并,而且这一过程是异步的。
考虑一个情况,一个事务已经向数据库中写入了一些数据,但是没有提交,而恰好这时候又触发合并了,合并时会新建一个数据文件,于是该事务的后半段数据就写入了新文件中,并成功提交。合并时,之前的文件会被归档然后清理掉其中的无用数据。但是,这个事务的前半段数据在合并时是扫描不到提交记录的,那么它就会被清理掉,这样一来只有事务的后半段数据持久化了。这个过程就是一个事务被截断了。如何避免这种情况,最简单的方法是用一个互斥锁让事务与合并互斥,这样做的代价很明显,会导致合并操作阻塞其它事务的读写行为,如果数据量多了的话合并操作是非常耗时的。我的解决方案是合并操作之前必须要等待当前所有的活跃事务执行完毕,同时阻塞新事务的开启,然后再去创建新的数据文件,文件创建完成后让阻塞的事务恢复运行。这样做虽然同样会阻塞事务,但它等待的时间是活跃事务的执行时间+创建新数据文件的时间,真正的合并操作依旧是异步的,而使用互斥锁的等待时间是一整个合并操作的时间。
其实还有一种解决方案,如下图
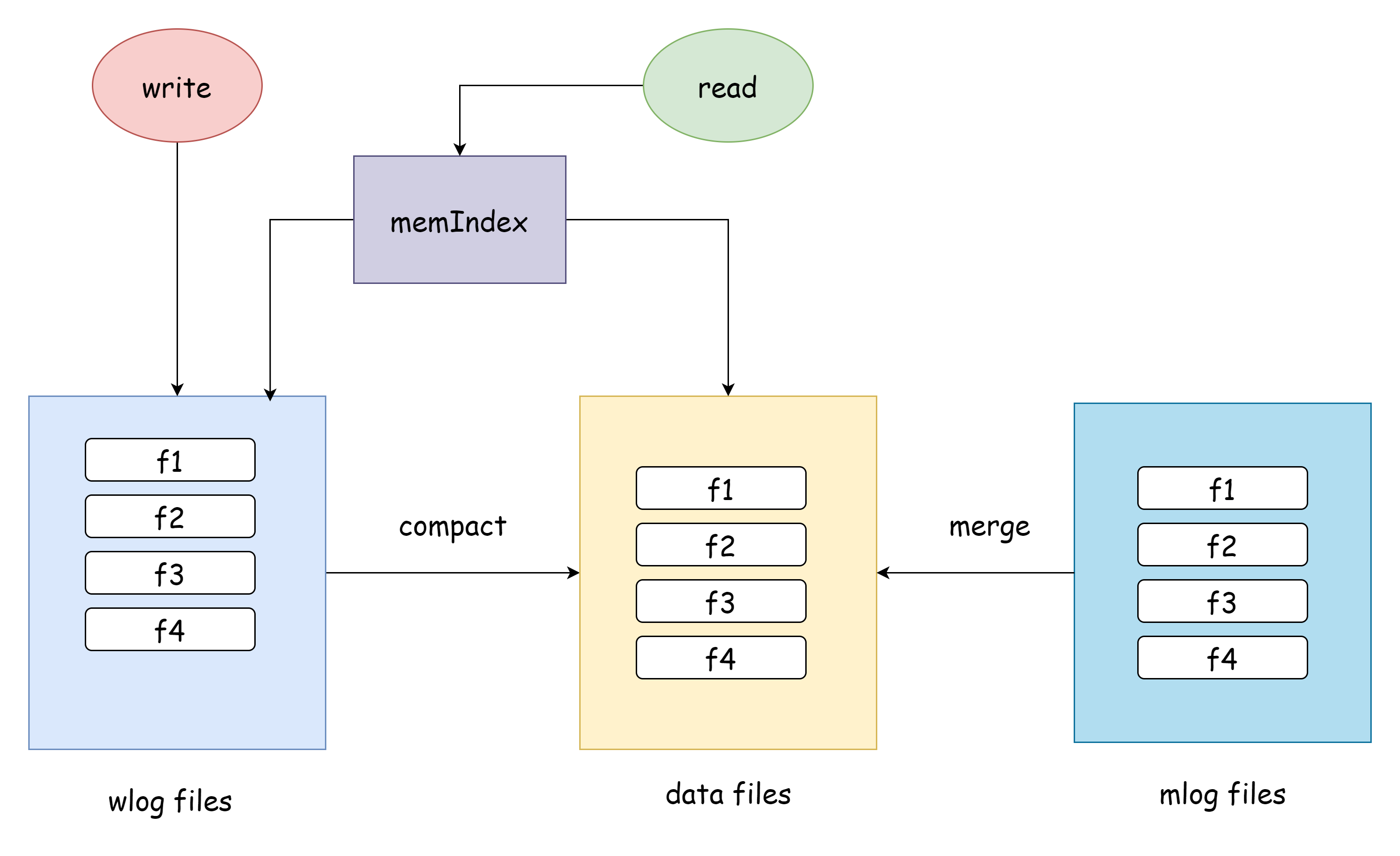
它采用的方案是把读和写的文件分开了,其实这就是我早期的设想。事务的修改首先被写入到wlog中,这时内存索引存储的是wlog中的位置索引,然后到了一定触发点将日志中的数据compact到data中,再更新内存索引为data中的位置索引,data是只读的,除了merge操作外不做任何修改。这样做其实依旧会发生上述提交的事务截断的情况,但compact阻塞的成本要比merge低很多,是可以接受的。因为每一次compact过后wlog的数据都会被清空,compact不会遍历所有数据,而merge总是会遍历整个data files,compact和merge操作也并不互斥,可以同时进行。这个方案最终没有被采纳,一是因为当我发现这个bug的时候已经写的差不多了,要改动的话会动非常多的东西,二是它还是会出现事务截断的情况,并且在compact的时候依旧需要阻塞事务,还会让整个过程变得更复杂。
下图是实际上应用的方案
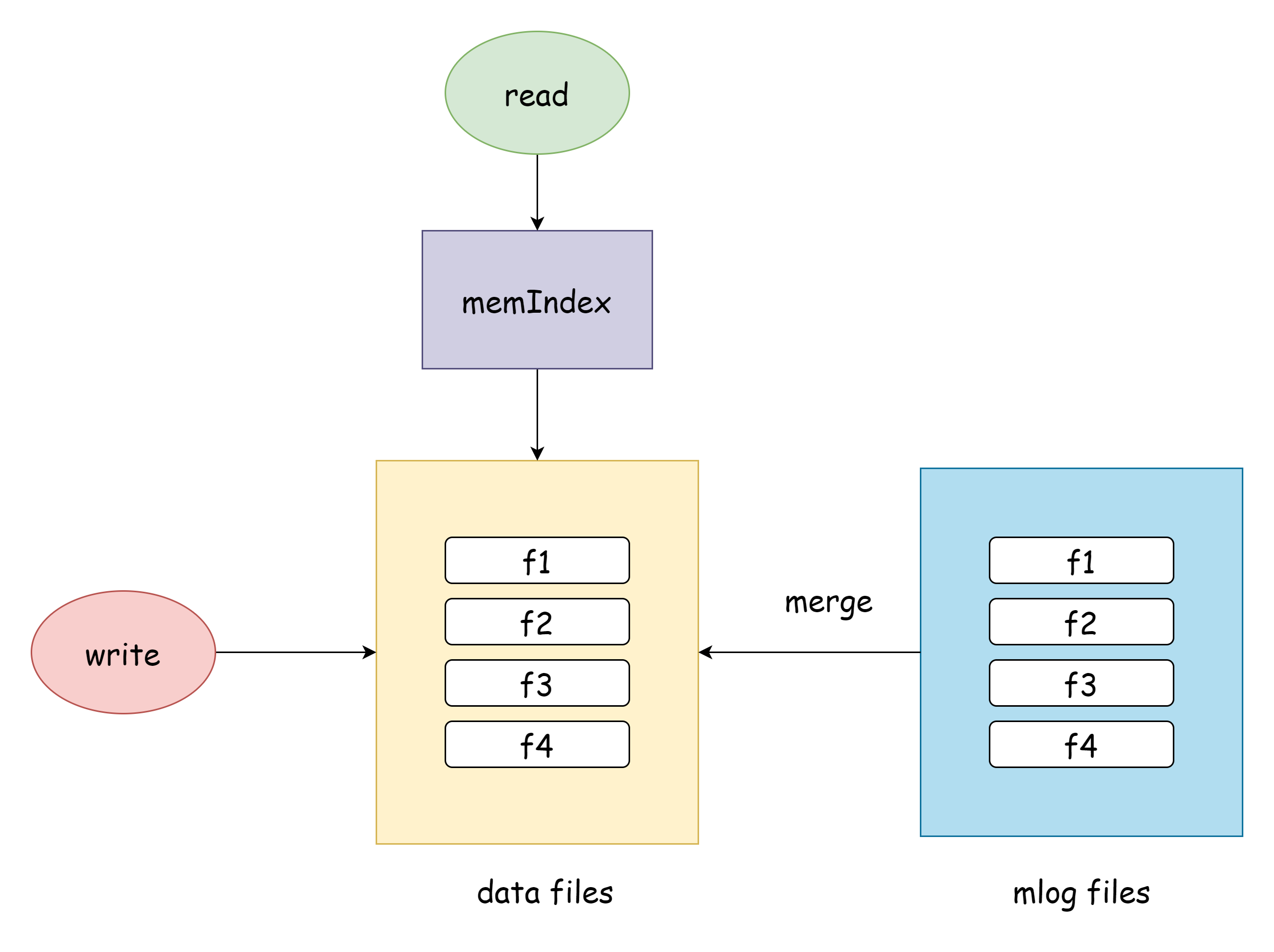
可以看得出来其实是把事务日志和数据文件合成一个了,因为bitcask数据文件的性质本身就跟事务日志一模一样。
备份
备份的实现思路就非常简单了,Bitcask实例就是一个文件夹,直接把当前文件夹打包成一个压缩包,就完成了备份,日后如果要恢复到备份状态的话,就直接解压缩到数据目录就好了。解压缩是用tar gzip来实现,它的兼容性会更好些。
监听
数据库总共有几种事件
- 更新事件
- 删除事件
- 回滚事件
- 备份事件
- 还原事件
- 合并事件
可以用一个队列来存放这些事件,上述操作成功后,会向队列中发送消息,队列会将这些消息转发给用户已创建的监听器,监听器的本质就是一个带缓冲的通道,所以这就是一个极简的消息队列的实现。用户在创建监听器时可以指定监听哪些消息,如果不是想要的消息就不会发送给该监听器,并且用户创建的监听器被维护在数据库中的监听器列表中,当消息队列有新的消息时,会遍历整个列表逐个发送消息,对于用户而言,只对其暴露一个只读的通道用于接收事件。其实这就是一个极简版的消息队列实现。
总结
这个简单的数据库花了我大概一个月的时间,从11月10日到12月2日结束,在过程中Wal的实现以及事务的支持卡了我最久,最后终于实现了预期的所有功能,但距离使用仍然需要不断的测试和完善。
仓库地址:246859/river: light-weight kv database base on bitcask and wal (github.com)
在这个过程中学习到了非常多的东西,最重要的就是存储模型Bitcask的实现,Wal的实现,事务的实现,这三个就是riverdb的核心点,总结下来就是
- 磁盘存储,磁盘存储的关键点在于数据的组织形式,以及Fsync调用时机,是性能与持久性之间的权衡
- 内存索引,而索引的关键点在于怎么去选择优化更好的数据结构,提供更好的性能,占用更少的内存。
- 事务管理,事务的关键点在于隔离性,是事务可靠性与事务并发量之间的权衡
至于其它的功能也就是在它们的基础之上衍生出来,只要这三个核心处理好了,其它的问题也就不算特别难处理。目前它还只是一个嵌入式的数据库,没有提供网络服务,要想使用只能通过导入代码的方式。riverdb现在等于只是一个数据库内核,只要内核完善了,在它的基础之上开发新的命令行工具或者是网络服务应该还算是比较简单的。